Quantifier l'incertitude pour améliorer les performances de spaCy
Dans cet article, nous allons voir comment la recherche d’incertitude d’un modèle assez complexe permet d’augmenter la précision de manière substantielle ainsi que la satisfaction de l’utilisateur final face à un système d’apprentissage supervisé.
Les sujets seront détaillés dans l’ordre suivant : contexte et première solution retenue, choix du modèle NER (Reconnaissance d’Entités Nommées), analyse des erreurs et enfin quantification d’incertitude pour améliorer les résultats. Les données présentées ne sont pas celles du projet pour des raisons de confidentialité.
Introduction
Dans un récent projet, j’ai eu comme objectif l’extraction d’information depuis un corpus de documents PDF. Après la lecture rapide d’une dizaine de documents, il s’est avéré que plusieurs champs recherchés suivaient un motif récurrents assez simple. Cela a permis la création un premier modèle très simple basé sur des expressions régulières. Le pipeline élémentaire suivant valide 70% des objectifs :
-
Convertir le PDF en fichier texte avec pdftotext
-
Effectuer quelques tâches de nettoyage (caractères spéciaux, lemmatisation)
-
Rechercher les motifs récurrents (par exemple “date de fermeture :”)
-
Extraire l’entité d’interêt qui suit le motif :
-
Soit avec une expression régulière (pour une date contenue dans la variable text :
re.findall(r'(\d+/\d+/\d+)', text)) -
Soit avec une table de correspondance (recherche d’un match entre la table et les N caractères suivant le motif)
-
Pour finaliser un premier rendu applicatif associé à ce pipeline, j’ai choisi streamlit - un projet qui permet de créer rapidement un rendu dans le navigateur. Les quelques lignes de code ci-après affichent une page ou l’on peut téléverser un document PDF et voir le résultat du modèle.
import streamlit as st
st.title('Extracteur d\'information')
pdf_file = st.file_uploader('', type=['pdf'])
show_file = st.empty()
if not pdf_file:
show_file.info('Sélectionnez un PDF à traiter.')
base64_pdf = base64.b64encode(pdf_file.read()).decode('utf-8')
pdf_display = f'<embed src="data:application/pdf;base64,{base64_pdf}" width="700" height="1000" type="application/pdf">'
st.markdown(pdf_display, unsafe_allow_html=True)
pdf_text = _convert_pdf_to_text_and_clean(pdf_file)
predictions = _run_model(pdf_text)
show_file.info(f"""Titre : {predictions['title']}
Date : {predictions['date']}""")
pdf_file.close()
![]() Figure 1 : Rendu applicatif avec streamlit
Figure 1 : Rendu applicatif avec streamlit
 Figure 2 : Aperçu du PDF et des prédictions
Figure 2 : Aperçu du PDF et des prédictions
En plus de rendre la tâche aisée, la communauté streamlit est active comme l’illustre la résolution du problème rencontré pour afficher le PDF.
Les deux conclusions de cette première partie sont - non pour me déplaire - devenues prosaïques : en début de projet, les idées les plus naïves apportent le plus de valeur et les outils de la communauté du logiciel libre sont admirables.
Le modèle NER
Certains champs à extraire présentent une plus grande complexité. Une simple analyse statistique ne permet pas de trouver de motif récurrent. Ils ne se trouvent ni à une place définie dans le texte ni n’ont de structure particulière. Quelques recherches sur internet nous guident rapidement vers les modèles de reconnaissance d’entités nommées NER qui permettent grâce à l’apprentissage supervisé d’associer des mots à des étiquettes.
Plusieurs librairies implémentent des surcouches facilitant la prise en main des modèles pour l’entraînement et l’inférence. J’ai opté pour spaCy qui met en avant son ergonomie et ses performances temporelles (~2h par entraînement sur un CPU 16 coeurs). Pour plus de détails quant au fonctionnement du modèle, il convient de se référer à la documentation, en particulier à cette vidéo.
Le dataset contient 3,000 documents partiellement annotés. Partiellement signifie ici que tous les champs cherchés ne sont pas annotés, en revanche lorsqu’un champ est annoté, il l’est sur la totalité du dataset. L’annotation a été effectuée de façon automatique en parcourant le code HTML de pages web (scrapping). Comme stratégie de validation croisée j’ai retenue un découpage avec 2,100 documents pour l’entraînement et 900 pour la validation. La précision recherchée est de l’ordre de 95% pour chaque champ.
Ci-après se trouve un exemple du format d’entrée attendu :
TRAIN_DATA = [
("Horses are too tall and pretend to care about your feelings",
{"entities": [(0, 6, "ANIMAL")]}),
("Who is Shaka Khan?",
{"entities": [(7, 17, "PERSON")]}),
("I like London and Berlin.",
{"entities": [(7, 13, "LOC"), (18, 24, "LOC")]}),
]
On remarque que chaque exemple est constitué d’un texte suivi de son étiquette délimitée par deux indices, celui de début et celui de fin. Les PDFs de notre base de données donnent des textes trop grands pour tenir dans la RAM. Une astuce pratique consiste à diviser le texte en morceaux. Néanmoins cela créé beaucoup d’exemples sans label (beaucoup de morceaux n’ont aucune entité d’intérêt). On qualifie le dataset de creux. Une fonction de rééquilibrage permet de pallier ce problème en sélectionnant un échantillon sans label avec une probabilité assez faible.
def _balance(data):
balanced_data = [row for row in data if len(row[1]['entities']) > 0 or np.random.rand() < .1]
return balanced_data
La probabilité 0.1 peut être ajustée, l’objectif étant d’atteindre une proportion raisonnable d’échantillon avec étiquette (50% dans notre cas). L’algorithme voit ainsi passer de nombreux exemples sans annotation mais n’est pas saturé par ces derniers.
Une fois les données formatées, la lectures des scripts d’exemple fournis permet de lancer l’entraînement d’un premier modèle. J’ai effectué quelques modifications préliminaires au code :
-
factoriser et tester le code
-
utiliser click pour les commandes
-
ajouter tqdm pour controller l’avancement des tâches chronophages
-
créer une fonction pour calculer notre métrique métier à chaque itération (par défaut seule la loss est calculée)
Regardons cette métrique de plus près. Pour qualifier les résultats on se restreint dans un premier temps à un unique champ (par exemple le titre du document). Ce qui intéresse notre utilisateur est l’affichage du champ “titre” peu importe le nombre de fois qu’il apparaît ou sa position dans le PDF (cf. Fig 2). Ainsi, notre prédiction sera un vote de majorité par document. Si le modèle prédit “[a, a, b]” comme étant des titres, la prédiction finale sera “a”. On rappelle que l’objectif est d’atteindre 95% de bonnes réponses.
Le premier entraînement de référence a donné 67%. Après avoir coupé les textes en morceaux, l’algorithme atteint 72%. Enfin, le rééquilibrage fait gagner 4 points de plus pour arriver à 76% de bonnes réponses.
Analyse des erreurs
Une étape cruciale en statistique inférentielle est l’étude des erreurs. Cette analyse possède une double vertu : mieux comprendre le modèle et se concentrer sur ses faiblesses pour l’améliorer. Examinons donc les PDFs dont le titre n’a pas été trouvé pour tenter d’investiguer les causes de ces bévues.
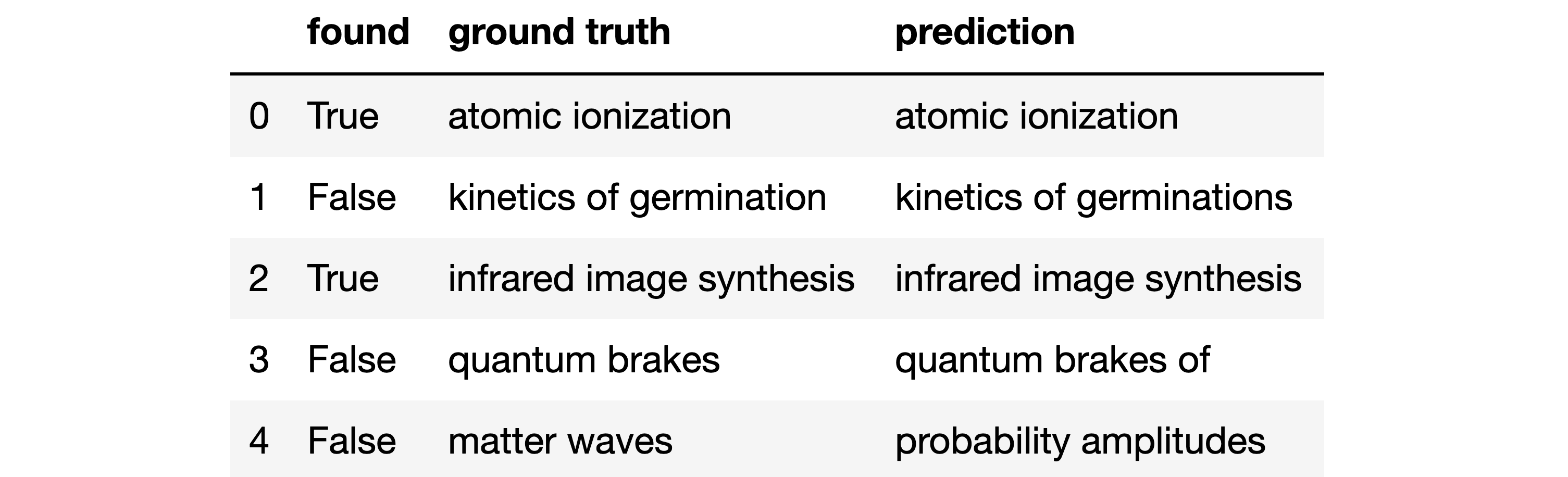 Figure 3 : Analyse des erreurs
Figure 3 : Analyse des erreurs
On souhaite se concentrer sur les erreurs, c’est-à-dire lorsque la colonne found est à False. Il y a 3 erreurs
dans la table ci-dessus :
-
Indice 4 : rien en commun entre la prédiction et la valeur réelle
-
Indice 3 : erreur plus subtile, le mot “of” est en trop
-
Indice 1 : encore plus proche, il y a un “s” en trop
D’un point de vue métier cela importe peu l’utilisateur lorsque l’erreur est petite. On peu donc construire une distance qui permet d’être plus flexible sur l’acceptation de la prédiction. La fonction ci-après vérifie que la valeur prédite n’est pas vide, puis accepte le résultat en cas d’inclusion ou si la distance de Levenshtein est inférieure à 5 (valeur arbitrairement choisie).
from Levenshtein import distance
def flexible_accuracy(x):
pred, gt = x['prediction'], x['ground truth']
return True if pred and distance(pred, gt) < 5 and (gt in pred or pred in gt) else False
df.apply(flexible_accuracy, axis=1).mean()
Sans n’avoir rien changé au modèle, nous passons à une précision de 82% pour nos utilisateurs. Il reste du chemin à parcourir mais quelques points ont été gagné sans effort.
Quantifier l’incertitude
A ce niveau du projet, les abonnissements sont moins évidents. Pour la concision de l’article, je ne vais pas m’attarder sur les essais non ou moins fructueux, parmi lesquels on trouve le travail sur les données et les réentrainements en modifiant les hyperparamètres.
Dans la continuité de la partie précédente et pour mieux comprendre les résultats du modèle, j’ai souhaité quantifier l’incertitude des prédictions. La facilité d’utilisation de la librairie a un coût, on le découvre lorsqu’on cherche à accéder aux probabilités. Néanmoins, le partage de connaissances au sein de la communauté permet à nouveau de trouver des éléments de réponse :
def _predict_proba(text_data, nlp_model):
proba_dict = defaultdict(list)
for text in text_data:
doc = nlp_model(text)
beams = nlp_model.entity.beam_parse([doc], beam_width=16, beam_density=0.0001)
for beam in beams:
for score, ents in nlp_model.entity.moves.get_beam_parses(beam):
for start, end, label in ents:
proba_dict[doc[start:end].text].append(round(score, 3))
return dict(proba_dict)
Cette fonction retourne un score de confiance compris entre 0 et 1 pour chaque groupe de mot identifié comme étant un titre.
{"le vrai titre du document": [1.0, 0.946, 1.0, 0.3],
"une apparence de titre": [0.123, 0.356, 0.65],
"des mots quelconques": [0.006],
"autre chose": [0.981]}
Pour plus de clarté on agrège en sommant les confiances, on normalise en divisant par la somme totale et on trie par ordre décroissant. La normalisation permet de comparer les confiances entre les documents.
{"le vrai titre du document": 0.605,
"une apparence de titre": 0.211,
"autre chose": 0.183,
"des mots quelconques": 0.001}
On considère naturellement le groupe de mot avec la plus grande confiance comme étant la meilleure prédiction. Traçons la densité de bonnes et mauvaises prédictions en fonction de l’incertitude.
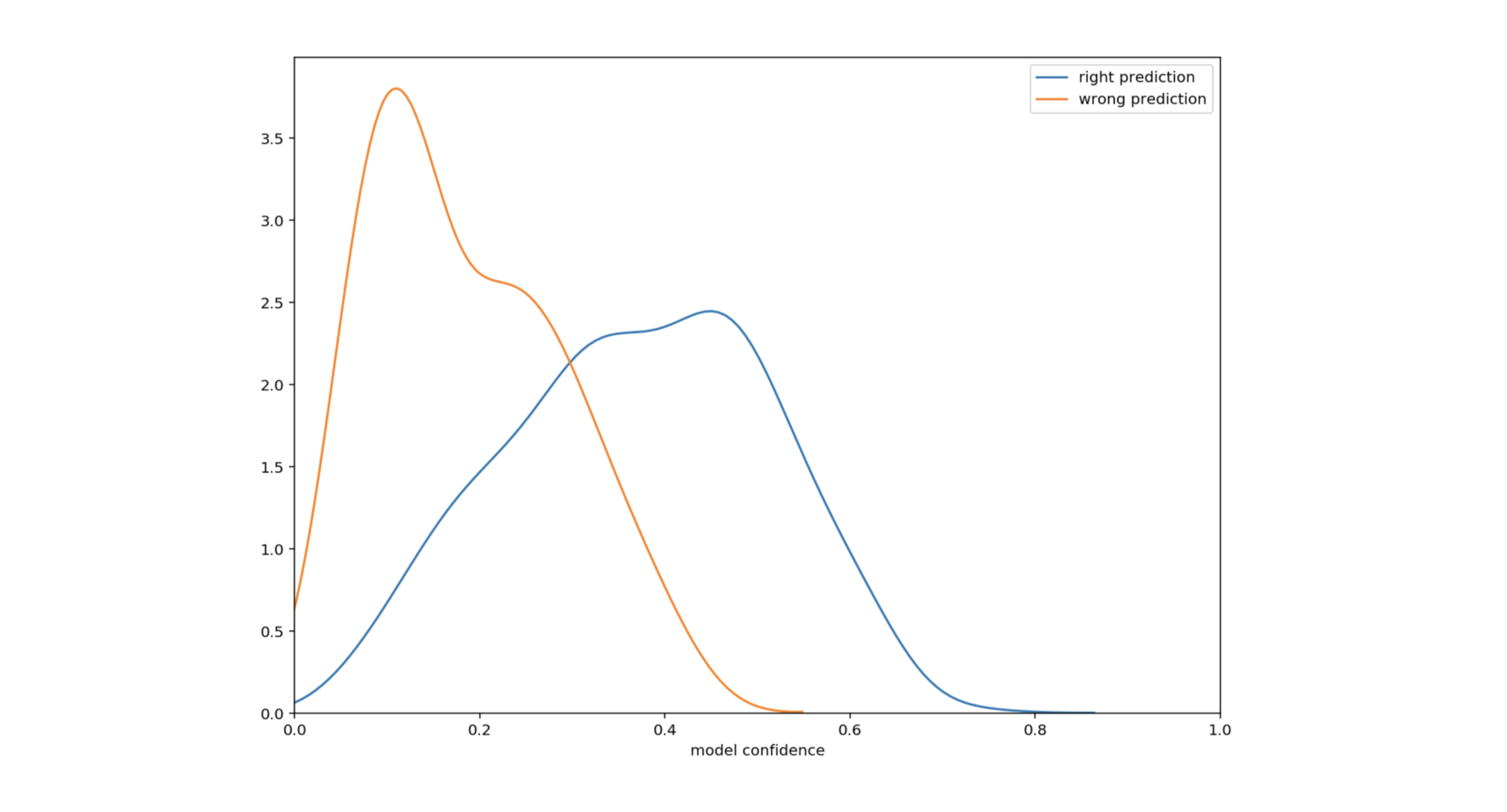 Figure 4 : Densité de prédictions en fonction de l’incertitude
Figure 4 : Densité de prédictions en fonction de l’incertitude
Ce tracé montre que l’incertitude est moindre lorsque les prédictions sont correctes. En particulier, pour une confiance supérieure à 0.4 (39% des cas), la précision est de 99%. Voila peut-être un moyen d’augmenter notre performance. Concentrons nous sur les confiances inférieures à 0.4 (61% des cas). En dessous de ce seuil, la précision tombe à 72%. Une analyse minutieuse de ces faibles confiances fait apparaître un motif : dans les 28% d’erreurs, la valeur avec la seconde plus grande confiance est souvent la bonne réponse. Cela est vrai dans 62% des cas. En d’autres termes, 62% des 28% d’erreurs contiennent la bonne réponse en seconde prédiction.
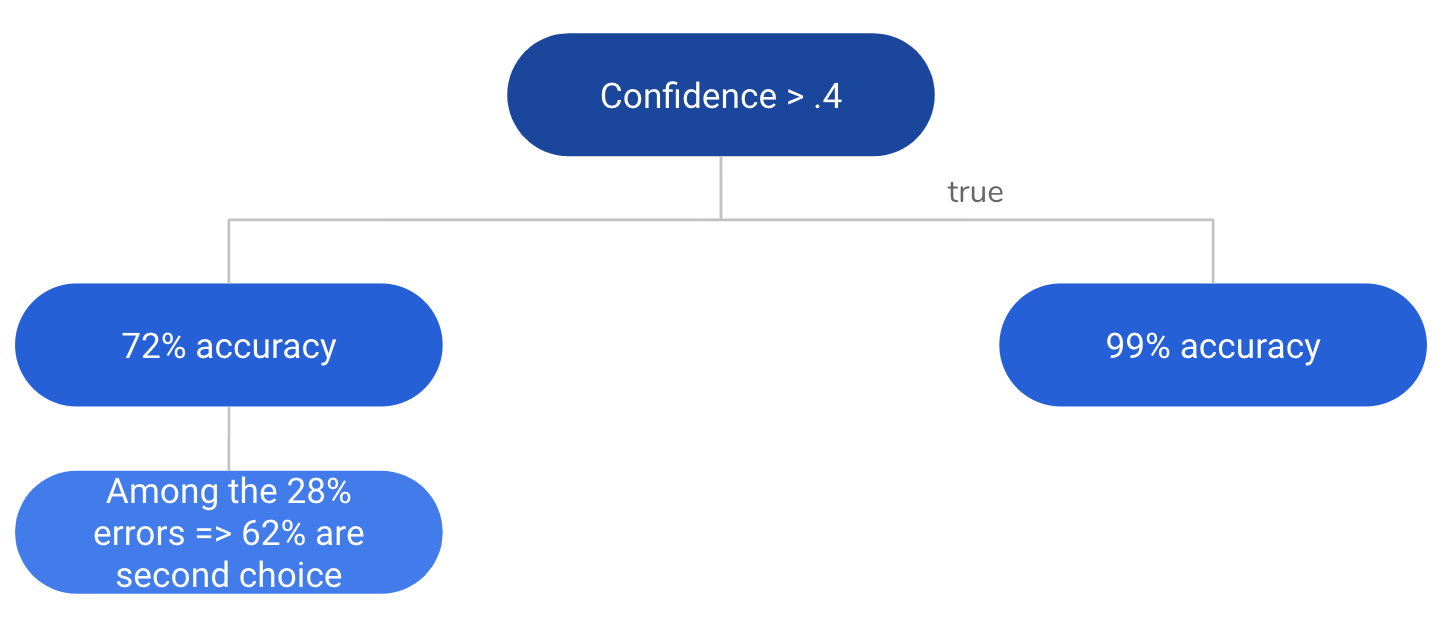 Figure 5 : Récapitulatif sous forme d’arbre
Figure 5 : Récapitulatif sous forme d’arbre
Il n’y a pas d’injonction à l’utilisation de la réponse pure de notre modèle. Le meilleur algorithme est celui qui est le mieux aligné avec le besoin utilisateur. Il s’avère ici que l’utilisateur privilégie la précision. On propose donc une règle basée sur la fig. 5 qui renvoie la prédiction lorsque la confiance est supérieur au seuil, dans le cas contraire, il renvoie les deux prédictions ayant les plus grandes confiances.
On peut calculer la précision avec laquelle l’utilisateur verra s’afficher la bonne réponse parmi celles proposées :
\[\begin{eqnarray} Accuracy_{Conf<0.4} &=& Accuracy_{FirstChoice} + Accuracy_{SecondChoice} \\ &=& 0.72 + (1-0.72) * 0.62 \\ &=& 0.89 \\ \end{eqnarray}\] \[\begin{eqnarray} FinalAccuracy &=& 0.39 * Accuracy_{Conf>0.4} + (1-0.39) * Accuracy_{Conf<0.4} \\ &=& 0.39 * 0.99 + 0.61 * 0.89 \\ &=& 0.93 \\ \end{eqnarray}\]On atteint ainsi 93% de précision. Pour plus de rigueur il conviendrait de créer un autre ensemble disjoint de validation et vérifier ces performances.
Conclusion
Le but n’est pas tout à fait atteint mais le gain est substantiel. Vincent Warderdam rappelle lucidement dans cette présentation qu’il est sain de “prédire moins mais prudemment”. Se servir de l’information d’incertitude est profitable dans une pléthore de cas d’usage. Il suffit de convenir avec l’utilisateur des conditions. Il n’aurait pas été convenable par exemple dans notre exemple de donner les 5 prédictions les moins incertaines car l’utilisateur aurait eu trop d’information à traiter.
La transparence de l’incertitude du modèle est sans doute un levier pour augmenter la satisfaction des utilisateurs. C’est en dévoilant ses imperfections qu’un algorithme peut gagner la confiance des utilisateurs.
À retenir :
-
Commencer avec un premier modèle simple et une boucle de rétroaction courte : que peut-on faire sans algorithme d’apprentissage ?
-
Adapter et assouplir le modèle et la métrique au cas d’usage
-
Utiliser l’incertitude :
-
se concentrer sur les cas les plus incertains
-
informer l’utilisateur lorsque le modèle n’est pas confiant
-
Pour aller plus loin :
-
Rechercher les nombre minimal de données à partir duquel le modèle spaCy converge (pour ajouter des nouveaux champs)
-
Essayer d’améliorer les performances en moyennant avec un autre modèle NER comme huggingface ou allennlp lorsque la confiance est basse
-
Étudier les erreurs du point de vue de la données : problème d’échantillonnage pour les incertitudes élevées ?